
Crawl budget optimization involves optimizing the way a website is structured and maintaining its content to ensure that search engines are able carnally to crawl and index the most important pages, while also avoiding wasting resources on low-value or duplicate pages.
This can hamper your SEO campaigns. The landing page you just improved might need to be indexed. It’s then time to maximise your crawl budget.
In this article, we’ll explain what a “crawl budget” is and how to make as effective use of it as possible.
Table of Contents
- How do Crawlers Work?
- What is Crawl Budget?
- How to check Crawl Budget in Google Search Console?
- Factors affecting it & How to solve them
- Should you worry about your Content getting hampered?
- Myths and facts
How do Crawlers Work?
Crawlers, a type of programme, are responsible for building the majority of the search index.
Similar to how you would if you were browsing the web for content, they automatically browse publically accessible web pages and follow links on those pages.
They navigate between pages, recording details about what they discover there and in other publicly available items in Google’s Search index.
Crawling Process: Crawling is the process by which Google’s search engine software, known as Googlebot, scans and indexes web pages on the Internet. Here’s a detailed explanation of how Google crawling works:
- Discovering URLs: Googlebot starts by finding new URLs to crawl. This can happen in a few ways. The most common is by following links on web pages it has already crawled. Google also receives lists of URLs to crawl from websites that use the Google Search Console tool.
- Crawling: Once Googlebot has found a new URL to crawl, it sends an HTTP request to the web server hosting the page. The server sends back the page content, including HTML, CSS, and JavaScript files.
- Rendering: Googlebot uses a rendering engine to process the HTML and execute the JavaScript on the page. This allows Google to index content that is dynamically generated by JavaScript.
- Indexing: After rendering, Googlebot extracts all the relevant information from the page, including text content, images, and other media. This data is stored in Google’s index, which is a massive database of all the content on the Internet.
- Updates: Google’s index is constantly updated as new pages are crawled and existing pages are re-crawled. The frequency of re-crawling depends on how often the content on the page changes.
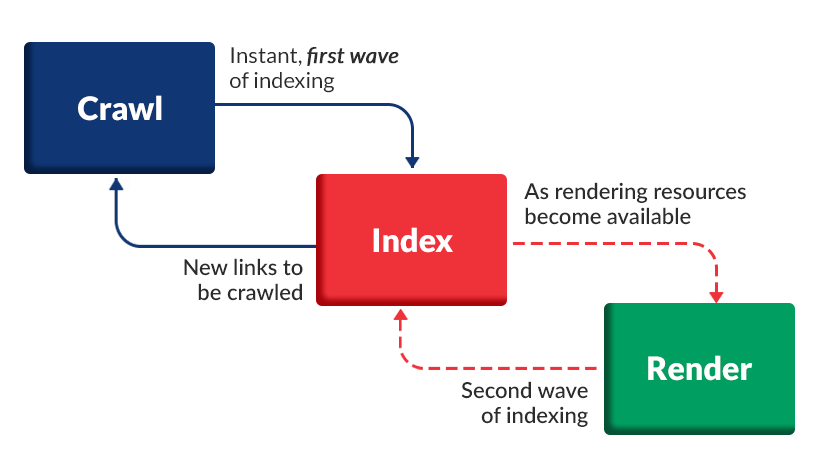
It’s important to note that Googlebot does not crawl every page on the Internet. It uses a number of algorithms to determine which pages to crawl, how often to crawl them, and how to prioritize them in the index.
Websites can also provide guidance to Googlebot through the use of a file called robots.txt, which tells Google which pages to exclude from crawling.
What is Crawl Budget?
Crawl Budget refers to the number of pages on a website that a search engine is willing to crawl and index.
It’s the number of resources (such as time and computing power) that a search engine is willing to allocate to visit and analyse a website. The budget is limited, and the search engine uses it to determine which pages to crawl and how frequently.
A website’s crawl budget optimization is influenced by several factors, including the website’s size, the complexity of the site’s architecture, the number of internal and external links, the speed of the website, and the overall load on the search engine’s servers.
It’s important to understand that the crawling budget is a finite resource, and it’s critical to optimise it to maximize the visibility and ranking of a website’s pages in search results.
To do this, website owners can use techniques such as limiting the number of low-quality pages, ensuring that the website’s architecture is clear and easy to navigate, and improving the website’s speed and performance.
Additionally, website owners can use tools such as Google Search Console to monitor the crawling budget and make changes to improve.
Two main elements determine the crawl budget: crawl capacity limit and crawl demand.
Crawl Rate Limit
Search engines have crawl rate limits to prevent overloading websites. Check if the site is approaching or exceeding the crawl rate limit, which can result in a reduced crawl budget.
Crawl Capacity Limit depends on the following factors:
- Website traffic: If a website experiences a sudden surge in traffic, it may cause the server to slow down, which can lower the crawl capacity limit.
- Server resources: If the website’s server has limited resources, it may not be able to handle a high volume of requests from a web crawler, which can decrease the crawl capacity limit.
- Crawler behaviour: If a web crawler is configured to crawl a website more frequently, it may cause the crawl capacity limit to decrease.
- Time of day: The crawl capacity limit may vary depending on the time of day. For example, if a website experiences more traffic during peak hours, the crawl capacity limit may be lower during these times.
- Website updates: If a website makes significant updates or changes, such as adding new pages or content, it may increase the crawl capacity limit to accommodate the additional data.
These factors can all impact the crawl capacity limit, and it’s important for website owners and SEO professionals to be aware of them when optimizing their sites for search engines.
By understanding these factors, they can take steps to ensure that their websites are crawled regularly and effectively.

You can modify the Googlebot crawl rate in Search Console right away to lower the rate of crawling.
In summary, if your site is experiencing a crawl budget issue, you may see a decrease in the number of pages being crawled, an increase in crawl errors, poor internal linking, duplicate content, slow page speed, or an approach to or exceeding the crawl rate limit.
Crawl Demand
Crawl demand refers to the level of interest or priority assigned to a website by a search engine or web crawler.
It indicates how often the search engine or crawler should visit and index the pages of a website based on various factors such as the website’s content, freshness, popularity, and relevance to search queries.
Websites with higher crawl demand are crawled more frequently and thoroughly, which can improve their visibility and ranking in search results.
Crawl demand can be influenced by various factors such as:
- Size and Structure of the Website: Websites with more pages and complex structures require more resources to crawl and index, which can affect crawl demand. A site that is easy to navigate with clear categories and well-structured content is typically easier for search engine crawlers to navigate.
- Frequency of Content Updates: Websites that regularly update their content and add new pages tend to have higher crawl demand. This is because search engines want to ensure that their index is up to date with the latest content available.
- Server Capacity and Response Time: Websites that have slow loading times or experience downtime frequently may not be crawled as frequently as they should. Search engines want to provide users with a positive experience, and a slow website can negatively impact user experience.
- Importance and Relevance of the Website’s Content: Websites that have high-quality, relevant content that meets user search queries are more likely to be crawled frequently by search engines. Search engines prioritize websites with quality content that is relevant to user queries.
- Backlink Profile: The quality and quantity of backlinks pointing to a website can also influence crawl demand. Websites with a strong backlink profile tend to have higher crawl demand, as search engines view them as more authoritative.
- Historical Crawl Data: Search engines track how frequently they crawl a website and adjust their crawl demand based on past performance. Websites that have been crawled frequently in the past tend to have higher crawl demand, while those that are rarely visited may see a decrease in crawl demand.
- Search Engine Algorithm Updates: Finally, search engine algorithm updates can also affect crawl demand. Changes to search engine algorithms can alter how frequently search engines crawl and index websites. Websites that conform to these changes and meet the updated requirements may see an increase in crawl demand, while those that don’t may see a decrease.
In summary, several factors play a role in determining crawl demand, including the size and structure of the website, the frequency of content updates, server capacity and response time, the importance and relevance of the website’s content, the backlink profile, historical crawl data, and search engine algorithm updates.
Website owners should aim to create a website with high-quality content, a strong backlink profile, fast loading times, and a good user experience to maximize crawl demand.
How to check Crawl Budget in Google Search Console?
Google Search Console is a valuable tool that website owners can use to optimize and manage their website’s crawl budget. The following steps can help you use Google Search Console to manage your website’s crawl budget management:
Step 1: Log in to Google Search Console and follow the steps Indexing > Pages > Here you will see pages on your website Not Indexed and Indexed pages.

Step 2: Go to Search Console > Setting > Crawl Stats > Open Report. There you can see Googlebot’s activity over the last 90 days.

Step 3: Then take note of the average pages that are crawled per day.
Step 4: Divide the number of pages by the “Average crawled per day” number.
Step 5: If your result is over 10, you need to optimize your crawl budget value. If you get a value below 3, there is no problem.
If we calculate from our example, that the value of the 6 Feb 2023, indexed page is 29867; We see that the total number of pages scanned on 6 Feb 2023 is 3476. When we calculate our values according to our formula, we can find that the result is 8.592.
Factors affecting it & How to solve them
Google claims that low-value URLs are the main problem affecting crawl budget management.
When there are too many URLs on the crawler’s path that are of little or no importance but still exist, the budget becomes depleted and Googlebot is unable to access more crucial resources. Let’s learn how to optimize crawl budget:
1. Faceted Navigation in Crawl Budget
Faceted navigation is a method of filtering and categorizing content on a website by using different attributes or facets, such as price range, brand, color, size, and so on.
It can affect crawl budget because search engine crawlers may see multiple URLs for each facet, leading to a larger number of pages to crawl.
To optimize crawl budget for faceted navigation, it is important to use techniques such as rel=canonical, meta robots tags, and robots.txt to control which pages get crawled and indexed.
Faceted navigation can create problems for crawl budget in a few ways.
- First, it can lead to a large number of URL variations that search engines may try to crawl, such as different combinations of facet values, which can cause a dilution of the crawl budget.
- Second, it can create many low-quality pages with thin or duplicate content that can negatively affect the website’s overall quality and authority.
- Third, it can lead to indexing of pages that are not relevant to searchers, which can result in poor user experience and lower search engine rankings. Therefore, it is important to optimize faceted navigation to ensure that only high-quality, relevant pages are crawled and indexed.
How to overcome?
To overcome faceted navigation problems in crawl budget, here are some best practices:
- Use canonical tags to indicate the preferred URL for search engines to index.
- Use noindex tags to prevent low-quality or duplicate content pages from being indexed.
- Use rel=prev/next tags to group paginated content together and avoid duplicate crawling.
- Implement robots.txt to block search engine crawlers from accessing certain facets or parameters that don’t add value to the user experience.
- Utilize URL parameters consistently and avoid creating unnecessary variations.
- Optimize meta titles and descriptions for each faceted page to make them more unique and useful for searchers.
- Monitor crawl errors in Google Search Console to identify and fix issues with faceted navigation pages.
2. Session Identifiers
Session identifiers are unique strings of characters that are generated by web servers to track individual user sessions. These identifiers are often included in URLs and can cause issues for search engine crawlers and crawl budget.
Factors affecting:
To overcome session identifier problems in crawl budget, you can implement the following best practices:
- Use canonical tags: Use canonical tags to indicate the preferred URL for search engines to index, and ensure that session identifier URLs are canonicalized to the main URL. This can help to prevent duplicate content issues and improve crawl budget.
- Implement URL parameters correctly: Ensure that URL parameters, including session IDs, are implemented correctly and consistently throughout the website. Avoid using different URL parameters for the same content, which can result in the creation of multiple URLs.
- Use robots.txt: Use robots.txt to block search engines from crawling session ID URLs or other non-essential parameters that don’t add value to the user experience.
- Implement 301 redirects: Use 301 redirects to redirect session ID URLs to the main URL or canonical version of the page. This can help to consolidate link equity and prevent duplicate content issues.
- Use a consistent URL structure: Use a consistent URL structure for session-based pages, such as using a separate subdomain or directory, to prevent duplicate content issues and improve crawl budget.
How to overcome:
To overcome session identifier problems in crawl budget, website owners can implement URL parameter handling techniques such as using canonical tags or robots.txt to block search engines from crawling and indexing session ID URLs.
Additionally, implementing a consistent URL structure for session-based pages, such as using a separate subdomain or directory, can help to prevent duplicate content issues and improve crawl budget.
3. Server Log File Analysis
Server log analysis is the process of examining the logs generated by web servers, application servers, or other types of servers to extract useful information and insights about the performance, behavior, and usage of the server and the applications it hosts.
These logs are text files that record various events and actions that occur on the server, such as HTTP requests, error messages, server responses, user sessions, and more.
Log analysis can help identify and diagnose issues with the server, such as errors, security breaches, or performance bottlenecks. It can also provide valuable information about the traffic patterns, user behavior, and usage trends of the server and its applications, which can be used to improve the user experience, optimize server resources, and inform business decisions.
To perform server log analysis, various tools, and techniques can be used, such as log file parsers, data visualization tools, machine learning algorithms, and more.
The analysis process typically involves filtering, parsing, and aggregating log data, applying statistical or machine learning models to identify patterns or anomalies, and presenting the results in a user-friendly format, such as dashboards, reports, or alerts.
Server log analysis reports can show various information about the requests made to a server, including:
- The IP address of the client making the request
- The time and date of the request
- The HTTP method (e.g. GET, POST) used in the request
- The URL and HTTP version requested
- The response status code (e.g. 200, 404) and any error messages
- The amount of data transferred in the request and response
- The user agent string, indicating the type and version of the client software used to make the request
Additional information that can be logged and analysed includes:
The referrer, indicating the page that linked to the requested resource
The server hostname and port number
Information about the server software and configuration
Any cookies sent with the request or set in the response
Custom variables and tags added to the log by the server or application code.
4. Orphan Pages
These are web pages that are not linked to from any other pages within the same website.
On the other hand, crawl budget refers to the amount of time and resources that search engines allocate for crawling and indexing a website’s content.
There are several factors that can contribute to the presence of orphan pages and their impact on the crawl budget. Some of these factors include:
- Poor website architecture: A website with a disorganized or complex structure can make it difficult for search engines to discover and crawl all pages, leading to orphan pages.
- Broken internal links: Internal links that lead to non-existent or broken pages can create orphan pages.
- Duplicate content: Multiple versions of the same content can create confusion for search engines and cause them to overlook important pages.
- Redirect chains: A series of redirects that eventually lead to a page can use up crawl budget and prevent the search engine from discovering other pages.
- Low-quality content: Pages with thin or poor-quality content may not be deemed important by search engines and could be overlooked in the crawl.
- Low authority: Pages that are not linked to by other pages or have a low number of external links may be considered less important by search engines, which can affect the crawl budget.
There are several steps you can take to overcome the problem of orphan pages in crawl budget:
- Improve your website architecture: Ensure that your website is well-organized and has a clear hierarchy of pages. Use internal linking to make it easy for search engines to discover and crawl all pages on your site.
- Fix broken internal links: Regularly audit your website for broken links and fix them promptly. This will help to prevent the creation of orphan pages.
- Avoid duplicate content: Ensure that your website has only one version of each page and use canonical tags to indicate the preferred version to search engines.
- Minimize redirect chains: Use redirects sparingly and ensure that they lead directly to the destination page to avoid wasting crawl budget.
- Improve the quality of your content: Ensure that your website has high-quality content that provides value to users. This can help to increase the importance of your pages in the eyes of search engines.
- Increase the authority of your pages: Build high-quality backlinks to your pages to increase their importance and visibility to search engines.
5. Hacked Pages
Hacked pages refer to web pages on a website that have been compromised or infiltrated by malicious actors without the website owner’s knowledge or permission. These pages can be used for various illicit activities such as phishing, malware distribution, or spamming.
Hacked pages can negatively impact a website’s crawl budget, which refers to the amount of resources allocated by search engines to crawl and index a website’s pages.
There are several factors that can affect hacked pages problems in crawl budget:
- Number of hacked pages: The more hacked pages a website has, the more likely it is to experience crawl budget issues as search engines may reduce the resources allocated to the site.
- Severity of the hack: The severity of the hack can also impact crawl budget. For example, if a website is hacked with malware, search engines may flag the site as unsafe and crawl it less frequently.
- Quality of the website’s security: A website with poor security measures is more vulnerable to hacking and may have more hacked pages. Search engines may also perceive a website with poor security as risky and reduce its crawl budget.
- Frequency of hacking incidents: If a website has a history of being hacked, search engines may become more cautious and reduce its crawl budget to prevent indexing of potentially harmful content.
- Response time to hacked pages: If a website owner fails to detect and fix hacked pages in a timely manner, search engines may reduce the website’s crawl budget until the issue is resolved.
Here are the steps to overcome hacked pages problems in the crawl budget:
- Identify and remove the hacked pages from your website.
- Use the Google Search Console to request a malware review for your site.
- Submit a sitemap to Google to help it understand the structure of your site and crawl it more efficiently.
- Use the “Disallow” directive in your robots.txt file to block search engines from crawling any compromised or irrelevant pages.
- Implement strong security measures, such as two-factor authentication, to prevent future hacks.
6. Infinite Spaces and Proxies
Googlebot will make an attempt to crawl nearly unending lists of URLs known as infinite spaces. Numerous things can lead to infinite spaces, but the site search’s auto-generated URLs are the most frequent.
Some websites feature on-site searches on their pages, which generates an almost endless amount of low-value URLs that Google will consider crawling.
Google offers some solutions for handling endless spaces. One is to delete all of the links in those categories from the robots.txt file. By doing this, Googlebot won’t be able to access those URLs right away, freeing up crawl money for other pages.
7. Too Many Redirects and Broken Links
Broken links are usually frustrating for both your users and the crawlers. Every page that the search engine bot indexes (or attempts to index) costs crawl money.
In light of this, if you have a lot of broken links, the bot will spend all of its time trying to index them and won’t get to any quality or relevant pages.
Ways to overcome:
- Regularly check your website for broken links and fix them: Use a tool like Google Search Console or a broken link checker to identify broken links on your website, and then update or remove them as needed.
- Use permanent redirects (301s): If you need to redirect visitors from an old URL to a new one, use a permanent redirect (301). This will signal to search engines that the old page has permanently moved to a new location, and they will transfer the page’s authority and rankings to the new URL.
- Use relative links: Instead of using absolute links that point to a specific URL, use relative links that are based on the website’s file structure. This can help prevent broken links if the domain or URL structure changes.
- Use a plugin or tool to manage redirects: If you have a large website with many pages, it may be helpful to use a redirect management tool or plugin to help you manage your redirects more efficiently.
- Monitor your website’s analytics: Regularly review your website’s analytics to identify pages with high bounce rates or other indicators of poor user experience. These may be caused by broken links or redirects, and you can use this information to identify and fix the underlying issues.
- Use canonical tags: If you have multiple URLs with similar content, you can use canonical tags to tell search engines
8. Low Quality and Spam Content
Making low-quality pages load faster won’t encourage Googlebot to crawl more of your site; instead, if we believe there is high-quality content missing from your site, we’ll likely raise our budget to crawl it. Google only wants to crawl high-quality content.
Here are some tips for making your pages and resources crawler-friendly:
- Use robots.txt to stop Googlebot from loading huge but unimportant pages. Make careful you only block non-critical resources, or those that aren’t necessary to comprehend the message of the page (such as decorative images).
- Ensure that your pages load quickly.
- Long redirect chains should be avoided because they hurt crawling.
- It is important to consider the load and run times for embedded resources like pictures and scripts as well as the time it takes the server to react to requests. Be mindful of the sluggish or huge resources needed for indexing.
9. Hierarchical website structure
A hierarchical website structure can have an impact on crawl budget, which is the amount of time and resources that a search engine’s crawler will allocate to crawling a website.
To ensure that all pages of a website are being crawled and indexed, it’s important to have a well-organized website structure with clear hierarchies, internal linking, and sitemaps.
This can help to ensure that all pages are easily accessible and that search engine crawlers can efficiently navigate the site.
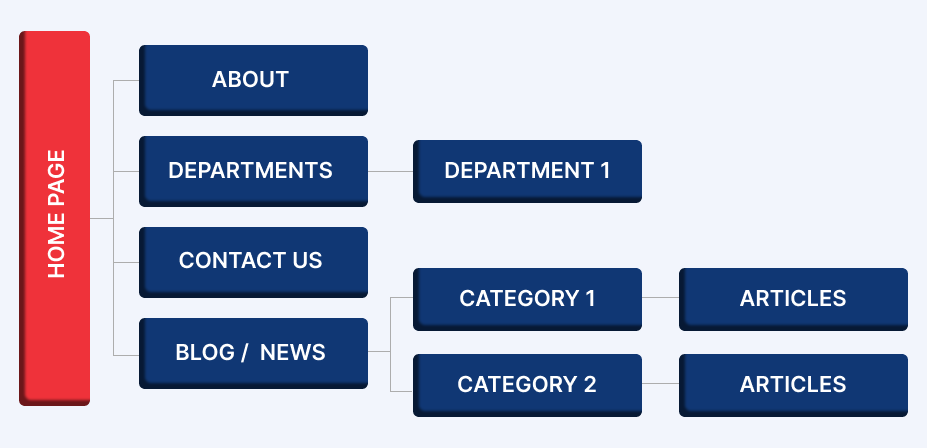
There are several steps that can be taken to overcome hierarchical website structure problems in crawl budget:
- Simplify the website structure: If the website structure is too deep, it’s important to simplify it by reducing the number of levels in the hierarchy. This can be achieved by grouping related pages together, removing unnecessary pages, and optimizing the internal linking structure.
- Improve internal linking: By optimizing internal linking, it’s possible to help search engines understand the hierarchy of the website and prioritize crawling important pages. This can be achieved by adding internal links from higher authority pages to deeper pages, ensuring that all pages are easily accessible and connected.
- Use a sitemap: Including a sitemap can help search engines to crawl the website more efficiently and ensure that all pages are being indexed. A sitemap provides a clear and organized overview of the website structure, making it easier for search engines to crawl the site.
- Optimize page load speed: Slow page load times can negatively impact crawl budget, so it’s important to optimize page load speed by optimizing images, reducing server response time, and using caching.
- Eliminate duplicate content: Duplicate content can confuse search engines and impact crawl budget. It’s important to ensure that each page has unique and relevant content. This can be achieved by removing duplicate pages, consolidating similar pages, and using canonical tags.
10. Should you worry about your Content getting hampered?
On popular pages, you typically don’t need to be concerned about the crawl budget. The pages that are not frequently crawled are typically those that are more recent, poorly linked, or don’t change much.
If Google needs to crawl a large number of URLs on your website and has allocated a large number of crawls, the crawl budget is not an issue. But suppose your website has 250,000 pages and Google only scans 2,500 of those pages per day. Some pages (like the homepage) will receive more crawling attention than others.
If you don’t take action, it could take up to 200 days for Google to discover specific modifications to your pages. The budget for the crawl is currently a problem. However, there is absolutely no problem if it crawls 50,000 times every day.
Remember, crawl budget for SEO is also an important factor. While it’s important to ensure search engines can efficiently crawl and index your website, it’s equally essential to focus on other SEO factors such as content relevance, backlink profile, mobile optimization, and user experience to achieve optimal organic search performance.
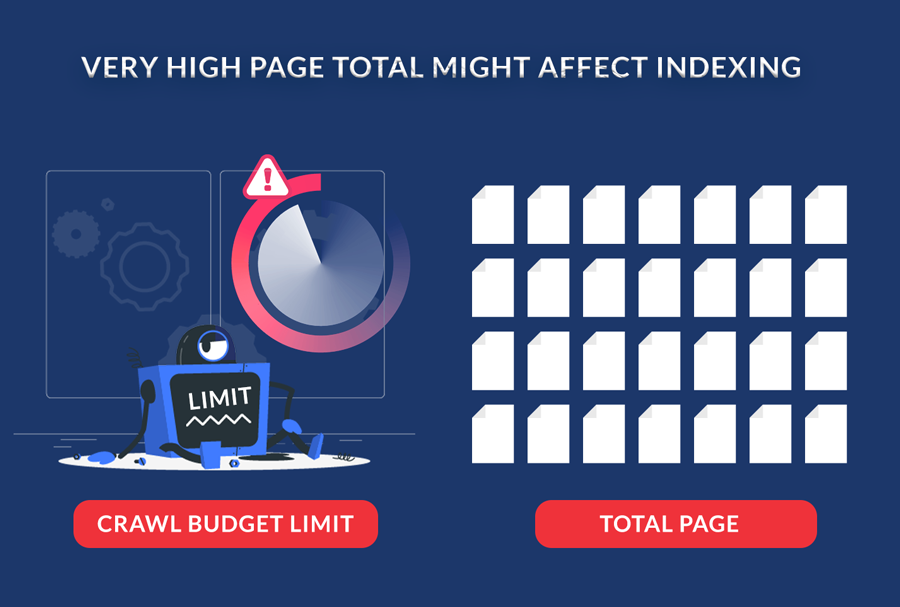
Nevertheless, there are a few situations in which you need to be mindful of the crawl budget:
- You manage a significant website: Google might not be able to find every page on your website if it has more than 10,000 of them (like an e-commerce site).
- Several new pages were just added: Having the crawl budget to quickly index all of the pages in a recently added portion of your website with hundreds of pages is important.
- Redirects and redirect chains in abundance: These drain your crawl budget.
For larger sites with millions of pages or sites that undergo frequent updates, the cost of the crawl might also be an issue. Generally speaking, if you have a lot of sites that aren’t crawled or updated as frequently as you’d want, you might want to look into speeding up crawling.
Google acknowledged
Google acknowledged on July 15, 2022, that it is having problems indexing fresh content and showing it in Google News and Search.
What is the issue all about?
The problem is that Google does not support fresh index content from websites that are published all over the internet. This includes any fresh content on news websites like this one, as well as fresh stuff from the Wall Street Journal, New York Times, and other online publications.
Google does appear to be crawling this fresh content, but because it hasn’t yet been indexed, neither Google News nor Google Search is displaying the results.

Is the issue resolved?
When Google fixes the error or has new information to give, it will tweet an update.
11. Monitor Index Coverage (Page indexing)
Log into your Google Search Console account to access the Report on Index Coverage (Page Indexing). Then, under the Indexing area, choose “Pages” from the option on the left:
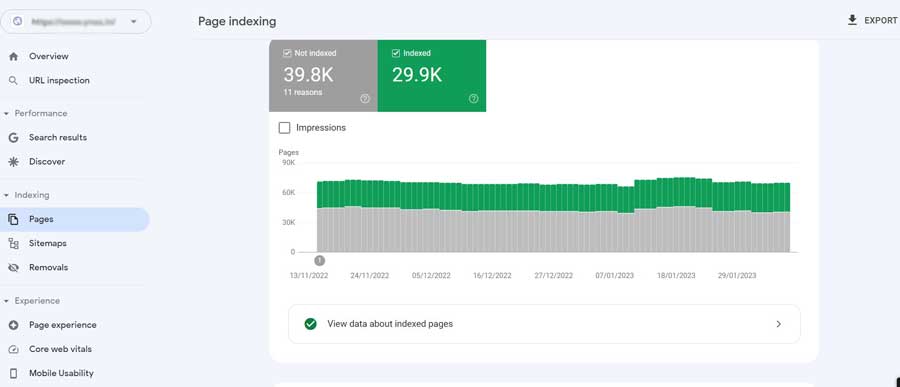
Indexed pages
Go to the View data about indexed pages area, which is immediately below the chart, to browse the URLs that are indexed on your website.
Here you can see the timeline of how the number of your indexed pages changed over time on a sorted chart.
You can look through the list of your indexed pages below the chart. But keep in mind that not all of them may appear to you as:
- The report shows up to 1,000 URLs, and
- A new URL may have been added after the last crawl.
By selecting a URL from the list and pressing Inspect URL on the right panel, you may inspect each URL to get more details.
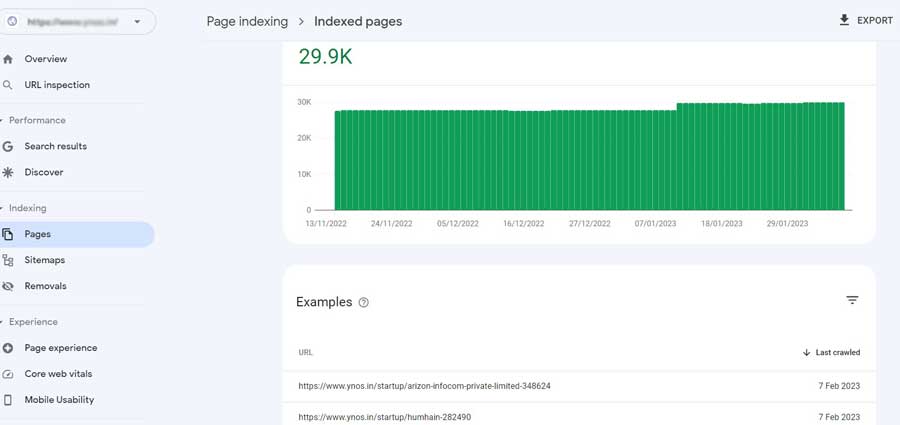
Not indexed pages
Look underneath the chart in the Page indexing report to find the information on the issues that were identified as Not indexed:
This section shows the cause of a certain status, the source (whether Google or your website is to blame), and the number of impacted pages.
You may also check the status of the validation; after resolving a problem, you can ask Google to verify the resolution.

Excluded by ‘noindex’ tag:
The “noindex” tag is an HTML meta tag that instructs search engine bots not to index a particular webpage or its contents in their search results.
When a search engine crawler visits a webpage with the “noindex” tag, it will not include that page in its index, and it will not appear in the search engine’s search results.
How to fix: If you have a page on your website that is excluded by the “noindex” tag and you want it to appear in search results, you will need to remove the tag.
You can do this by editing the page’s HTML code and removing the “noindex” meta tag from the page’s header. After you’ve made the changes, the page should be indexed by search engines and appear in search results.
Not Found (404)
Not Found (404) is an HTTP status code that indicates that the server can’t find the requested resource. This usually happens when a user tries to access a webpage that doesn’t exist or has been removed from the server.
To fix a 404 error, you can try the following steps:
- Check the URL: Make sure that the URL you entered is correct and complete.
- Refresh the page: Sometimes, the server might experience a temporary issue, and refreshing the page can help.
- Clear your browser cache: Cached pages can sometimes cause issues, so try clearing your browser cache and see if that resolves the issue.
- Check the server: If you are the website owner, check your server logs to see if there are any errors or issues that could be causing the 404 error.
- Create a custom 404 page: If you are a website owner, consider creating a custom 404 error page to provide users with helpful information and guidance on what to do next.
- Redirect the page: If the resource you are trying to access has moved to a new location, consider creating a redirect to the new URL.
If none of these solutions work, it could be a more technical issue, and you may need to consult a web developer or IT professional for assistance
Blocked by robots.txt
Blocked by robots.txt means that a search engine crawler or bot has been restricted from accessing specific pages or content on a website through the robots.txt file. This file is a text file that webmasters create to instruct search engine bots on what to crawl and what to ignore.
To fix this issue, you can try the following steps:
- Check the robots.txt file: Check the robots.txt file on your website to ensure that it is not blocking access to important pages or content. You can do this by visiting http://www.yourwebsite.com/robots.txt, where “yourwebsite.com” is the URL of your website.
- Remove the block: If you find that the robots.txt file is blocking a page or content that should be accessible to search engine bots, you can remove the block by modifying the file. You can do this by either removing the blocked content or adding an “Allow” directive to the file.
- Submit sitemaps: Submitting a sitemap to search engines can help ensure that all pages on your website are discovered and indexed. This can be done through Google Search Console or Bing Webmaster Tools.
- Wait for the next crawl: After you have made changes to your website, it may take some time for search engines to crawl and index your site again. You can check the status of your website in the search engine console to see when the next crawl is scheduled.
- Test with tools: You can use various online tools like Google’s Robots.txt Tester or Bing’s Robots.txt Analyzer to test and troubleshoot any issues with the robots.txt file.
- It is important to note that some pages or content may need to be blocked from search engine crawlers to protect sensitive information. Therefore, it is crucial to understand the implications of modifying the robots.txt file and to ensure that it is configured correctly.
Soft 404
A Soft 404 error occurs when a webpage is served with a 200 status code (which means the page was successfully retrieved) instead of the appropriate 404 status code (which indicates that the page was not found).
This can occur when the web server is not configured correctly to return the appropriate status code for missing pages, or when a content management system or website platform generates incorrect URLs.
To fix a Soft 404 error, you can try the following steps:
- Check the server configuration: Make sure that the web server is configured to return a 404 status code for missing pages. This can usually be done in the server settings or .htaccess file.
- Check for broken links: Use a tool like Google Search Console to identify broken links on your website, and update or remove them as necessary.
- Redirect pages to relevant content: If a page has been permanently removed, you can redirect the URL to a relevant page or content on your website. This will help preserve any link equity that the removed page may have had.
- Customize the 404 error page: Customize the 404 error page to make it clear to users that the page they were looking for is not available. Provide links to other relevant content on your website, and encourage users to explore your site further.
By taking these steps, you can reduce the number of Soft 404 errors on your website, improve the user experience, and ensure that search engines can properly index your content
Duplicate without user-selected canonical
Duplicate content without a user-selected canonical occurs when the same content is accessible through multiple URLs on a website, but no canonical tag has been implemented to tell search engines which version of the content should be indexed.
This can cause problems for search engines trying to determine the most relevant version of the content, and can result in lower rankings and reduced visibility in search results.
To fix duplicate content without a user-selected canonical, you can follow these steps:
- Identify duplicate content: Use a tool like Google Search Console or a third-party SEO tool to identify pages with duplicate content.
- Choose a canonical URL: Decide which version of the content you want to be the primary version, and add a canonical tag to that page’s HTML header. This tag tells search engines that this is the preferred version of the content and should be indexed.
- Implement the canonical tag: Add the canonical tag to the header of the primary version of the content. The tag should reference the URL of the canonical version of the page, like this: <link rel=”canonical” href=”https://www.example.com/canonical-page”>
- Monitor changes: Keep an eye on your search engine rankings and traffic after implementing the canonical tag. It may take some time for search engines to re-crawl and re-index your pages, but over time, you should see improved visibility for the primary version of the content
Alternative page with proper canonical tag
An alternative page without proper canonical is a version of a page that is intended to be served to users with specific characteristics, such as language or location, but does not have a canonical tag pointing to the primary version of the page.
This can cause search engines to treat the alternative version as a duplicate, which can result in lower rankings and reduced visibility in search results.
To fix alternative pages without proper canonical tags, you can follow these steps:
- Identify alternative pages: Use a tool like Google Search Console or a third-party SEO tool to identify pages with alternative versions.
- Choose a primary version: Decide which version of the page you want to be the primary version, and add a canonical tag to that page’s HTML header. This tag tells search engines that this is the preferred version of the page and should be indexed.
- Implement the canonical tag: Add the canonical tag to the header of the primary version of the page. The tag should reference the URL of the primary version of the page, like this: <link rel=”canonical” href=”https://www.example.com/primary-page”>
- Use hreflang tags: If you have alternative versions of the page in different languages or for different regions, use hreflang tags to tell search engines which version to serve to users based on their language or location.
- Update internal links: Update any internal links on your website to point to the canonical URL, rather than alternative versions of the page.
- Monitor changes: Keep an eye on your search engine rankings and traffic after implementing the canonical tag and hreflang tags. It may take some time for search engines to re-crawl and re-index your pages, but over time, you should see improved visibility for the primary version of the page
Page with redirect
A page with a redirect is a web page that automatically sends the user to a different page than the one they originally requested.
Redirects are often used to send users from an old page to a new page, or to direct traffic to a different page for some other reason.
Here are some steps you can take to fix a page with a redirect:
- Check the redirect type and make sure it is necessary.
- Identify any broken or incorrect redirects and fix them.
- Make sure the redirect is implemented correctly, and that it is not slowing down the page load time.
- Update any links or references to the old page to point to the new page.
- Use tools like Google Search Console or a web crawling tool to identify any remaining pages with broken or incorrect redirects.
- Test the page with the redirect to make sure it is working as expected
Server error
A server error is an error that occurs on the server-side of a website or web application, indicating that the server was unable to fulfill a request made by the client.
To fix a server error, you need to identify the root cause of the error.
Here are some steps you can take to fix a server error:
- Check the server logs for more information about the error.
- Check the server status to see if there is an outage or maintenance scheduled.
- Check the configuration files for any errors.
- Restart the server or service to see if it resolves the error.
- Check for any updates or patches that need to be installed.
- Check the database connection and make sure it is working properly.
- Test the server to see if the error has been resolved.
Crawled – Currently Not Indexed
“Crawled – Currently Not Indexed” typically refers to a situation where a search engine’s web crawler has discovered a web page or website but has not yet added it to its index. This means that the web page or website is not yet showing up in search results for relevant queries.
How to fix: If you want to ensure that your web page or website is indexed by search engines, you can take steps such as submitting your website to the search engine’s index, creating high-quality content, optimizing your website for search engine rankings, and building backlinks from other reputable websites.
Site’s page speed & performance
Page speed can impact the crawl budget by slowing down the crawl process. Sites with slow page speed can result in search engines crawling fewer pages in a given time frame.
You can also make use of the following tools to check your site speed & performance:
Google Page Speed Insights: is a web-based tool developed by Google that analyzes the performance and speed of a website.
The tool provides a score between 0 and 100 for both desktop and mobile versions of the website, based on various factors that impact its performance, such as server response time, browser caching, image optimization, and more.

Throughout the PSI report, color coding makes it easy to understand the areas where the page is performing well, still needs improvement, or is underperforming.
- Green = Good.
- Yellow = Needs Improvement.
- Red = Poor.
Additionally, the tool finds areas for optimization and provides detailed advice for advancement.

12. Core Web Vitals Assessment:
Core Web Vitals Assessment refers to the process of evaluating a website’s user experience using field data on its Core Web Vitals metrics.
They are a set of specific website performance metrics identified by Google that are related to user experience and they include:

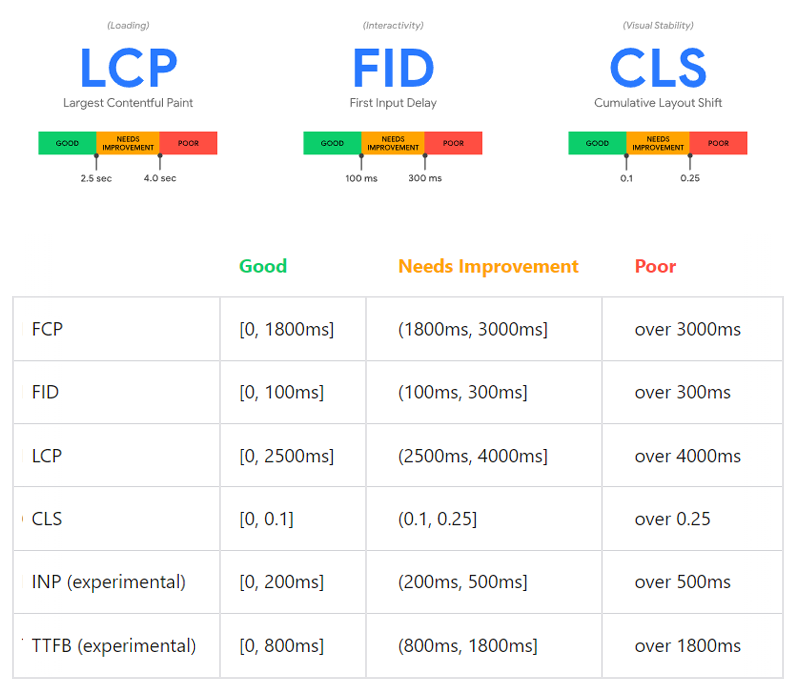
- First Input Delay (FID) is a user-centric performance metric that measures the time between when a user interacts with a web page for the first time (such as clicking a button or entering information in a form) and when the browser is able to respond to that interaction.
Good Score: <<100 ms
Reasons: Heavy JavaScript execution is the primary reason for a bad FID.
Solutions:
- Optimize JavaScript execution: FID is often caused by long-running JavaScript tasks that block the main thread.
- Minimize third-party code
- Optimize page loading speed
- Use a performance monitoring tool
- Max Potential First Input Delay (Max FID) is a performance metric that estimates the worst-case scenario for First Input Delay (FID) on a web page. It measures the longest possible delay that a user could experience when interacting with a page, even if that delay only occurs for a small percentage of users.
Good Score: under 100 milliseconds
Reasons: Minimal JavaScript, Caching, server response time, third party scripts, etc
Solutions:
- Optimize server response time
- Minimize JavaScript execution
- Optimize CSS
- Use efficient event handlers
- First Contentful Paint (FCP) is a web performance metric that measures the time it takes for a user to see the first visual element on a web page. This visual element can be anything from text, an image, or a background color.
Good Score: << 1 sec
Reasons: Large file sizes, slow server response time, unoptimized code, third party scripts.
Solutions:
- Remove unused CSS
- Avoid multiple page directs
- Avoid enormous network payloads
- Avoid an excessive DOM size
First Meaningful Paint (FMP): it is a web performance metric that measures the time it takes for the primary content of a web page to be displayed to the user.
The primary content is typically the part of the page that provides the most value to the user, such as the main article or the search results.
Good Score: << 2 sec
Reasons: Large or unoptimized pages, render-blocking resources, slow server response time, JavaScript execution, font loading
Solutions:
- Minify CSS
- Eliminate render-blocking resources
- Remove unused CSS
- Avoid eneormous network payloads
- Minimize critical request depth
Largest Contentful Paint (LCP): it is a web performance metric that measures the time it takes for the largest visible element in the viewport to be rendered on the screen.
The largest visible element is typically an image, a video or a block-level element such as a paragraph or a container.
Good Score: << 2.5 sec
Reasons: Render-blocking JavaScript & CSS, Client-side rendering, slow server response times
Solutions:
- Minify CSS
- Eliminate render-blockinh resources
- Remove unused CSS
- Reduce server response times (TTFB)
- Avoid multiple page redirects
- Ensuring text remains visible during webfont load
- Cumulative Layout Shift: This page metric measures the stability of a page. Simply said, if a web page’s information or elements suddenly jump in or change as you load it, begin reading it, or take any other action, it could be problematic for consumers’ viewing experiences.
Good Score: << 0.1
Reasons: images and videos without dimensions, ads and iframes, dynamically injected content, font loading, slow loading resources
Solutions:
- Eliminate render-blocking resources
- Minify CSS
- Remove unused CSS
- Preconnect to required origins
- Avoid enormous network payloads
- Avoid an excessive DOM size
- Time To First byte (TTFB) : A long waiting time indicates a slow time to first byte (TTFB). It is advised that you keep this under 200 milliseconds. A high TTFB points to one of two main problems. A server application that responds slowly or poor client-server networking
Good Scores: << 200ms
Reasons: server configuration, server location, high server load, large or unoptimized resources, third-party services
Solutions: Eliminate render-blocking services, Minify CSS, Remove unused CSS, Preconnect to required origins, Preload key requests, avoid enormous network payloads
Speed Index: Speed Index is a metric used to measure how quickly the visual content of a web page is displayed to the user.
It is calculated by analysing a video recording of the page loading process and measuring the average time it takes for visible parts of the page to appear.
Good Score: << 3 sec
Reasons: large or unoptimized resources, render-blocking resources, server response time, JavaScript execution time, Third-party services.
Solutions: Eliminate render-blocking resources, Minify CSS, Remove unused CSS, Avoid enormous network payloads, serve static assets with an efficient cache policy.
Myths and facts:
Now lets test our knowledge on the Crawl Budget:
Q1. My crawl budget may be increased by compressing my sitemaps.
- True
- False
Q2. I should maintain making changes to my page because Google prefers more recent material.
- True
- False
Q3. Google favours older material over newer stuff (older content has more weight).
- True
- False
Q4. Google dislikes query parameters and favours tidy URLs.
- True
- False
Q5. The more content your pages can display and load quickly, the more Google can crawl.
- True
- False

